
- Thank you received: 0
My pareidolia knows no bounds.
18 years 7 months ago #9262
by rderosa
Replied by rderosa on topic Reply from Richard DeRosa
While continuing my study of pareidolia, I have become convinced that we are embarking on a very complicated subject, that goes to the very heart of the Cognitive Sciences. As with just about anything in life, the more you know, the more you realize how little you know. Merriam-Webster defines "Cognitive Science":
Main Entry: cognitive science
Function: noun
: an interdisciplinary science that draws on many fields (as psychology, artificial intelligence, linguistics, and philosophy) in developing theories about human perception, thinking, and learning
This makes perfect sense to me, because I have long felt that to rely too heavily on philosophy would be like building the four corners of a house with only one 2x4 (or as they say in Missouri: tuba 4).
In my next message, I will tell you why I have come to this conclusion, and I will draw on the work of leading scientists in the field of Cognition, Behavioral and Brain Sciences.
I only have a glimmer, but that glimmer is telling me that "pareidolia" is a very strong candidate indeed, for an explanation of many, if not all of these Mars "faces".
rd
Main Entry: cognitive science
Function: noun
: an interdisciplinary science that draws on many fields (as psychology, artificial intelligence, linguistics, and philosophy) in developing theories about human perception, thinking, and learning
This makes perfect sense to me, because I have long felt that to rely too heavily on philosophy would be like building the four corners of a house with only one 2x4 (or as they say in Missouri: tuba 4).
In my next message, I will tell you why I have come to this conclusion, and I will draw on the work of leading scientists in the field of Cognition, Behavioral and Brain Sciences.
I only have a glimmer, but that glimmer is telling me that "pareidolia" is a very strong candidate indeed, for an explanation of many, if not all of these Mars "faces".
rd
Please Log in or Create an account to join the conversation.
- tvanflandern
-
- Offline
- Platinum Member
-
Less
More
- Thank you received: 0
18 years 7 months ago #9165
by tvanflandern
Replied by tvanflandern on topic Reply from Tom Van Flandern
<blockquote id="quote"><font size="2" face="Verdana, Arial, Helvetica" id="quote">quote:<hr height="1" noshade id="quote"><i>Originally posted by rderosa</i>
<br />"pareidolia" is a very strong candidate indeed, for an explanation of many, if not all of these Mars "faces".<hr height="1" noshade id="quote"></blockquote id="quote"></font id="quote">Most of us will stipulate that much. But it seems just as hard to prove they are pereidolia as to prove they are artificial.
Most faces in terrestrial landscapes are cartoonish or grotesque and made of few features. But a few are more detailed, and a very few, rare cases are heavily detailed. But on Mars, we seem to have numerous cases heavy on details, which defies the normal probabilities for pereidolia.
So excepting the small number of cases where an independent argument for artificiality is available, the main evidence for artificiality in most cases on Mars is statistical -- you can't get chance faces <i>that</i> good <i>that</i> often.
But I'm eager to hear what the experts have to say. So by all means, press on. -|Tom|-
<br />"pareidolia" is a very strong candidate indeed, for an explanation of many, if not all of these Mars "faces".<hr height="1" noshade id="quote"></blockquote id="quote"></font id="quote">Most of us will stipulate that much. But it seems just as hard to prove they are pereidolia as to prove they are artificial.
Most faces in terrestrial landscapes are cartoonish or grotesque and made of few features. But a few are more detailed, and a very few, rare cases are heavily detailed. But on Mars, we seem to have numerous cases heavy on details, which defies the normal probabilities for pereidolia.
So excepting the small number of cases where an independent argument for artificiality is available, the main evidence for artificiality in most cases on Mars is statistical -- you can't get chance faces <i>that</i> good <i>that</i> often.
But I'm eager to hear what the experts have to say. So by all means, press on. -|Tom|-
Please Log in or Create an account to join the conversation.
18 years 7 months ago #9166
by rderosa
Replied by rderosa on topic Reply from Richard DeRosa
(this one is a little long, so please bear with me)
One day I was searching the web via Google for "Faces" or "Face Studies" and various things of that nature, when I came across an interesting paper by the name of “Dr. Angry and Mr. Smile: when categorization flexibly modifies the perception of faces in rapid visual presentations by Philippe G. Schyns*, Aude Oliva* Department of Psychology, University of Glasgow,UK
I wouldn't attempt to summarize a paper of this complexity here, but for anyone who is interested, it is readily available on the internet. Here's one site: cvcl.mit.edu/Papers/Schyns-Oliva99.pdf#s...and%20Mr.%20Smile%22
The study uses something called "hybrid images", where two different categories of face features are overlapped at different spatial frequencies. Here is an example of a hybrid, from the paper (step back from the screen, and you will see Dr. Angry turn into Mr. Smile, and vice versa):
(From PG Schyns, A. Oliva99)

As I read through this paper, I started to get the distinct impression that this was somehow related to my study of pareidolia, although there is no mention of the subject. After reading it, I wrote to Dr. Schyns at his email address on the paper, at the University of Glasgow's Department of Psychology. I told him that I had just read “Dr. Angry and Mr. Smile” and that how I really stumbled upon it accidentally, while trying to find out more about pareidolia, and asked him if he knew of any studies being done on pareidolia. He was on vacation at the time, but when he got back, he kindly responded and sent me a copy of a 5 page paper by the called: "SUPERSTITIOUS PERCEPTIONS REVEAL PROPERTIES OF INTERNAL REPRESENTATIONS" Frederic Gosselin and Philippe G. Schyns (sorry, but I have no link, so anyone interested will have to request a copy)
He asked me not to be put off by the title, and that he thought I might find it relevant to my question. He was right! It is very much relevant.
I'll copy the Abstract, and then give a brief description of the experiment, results, and conclusions.
Abstract (Superstitious, Frederic Gosselin and Philippe G. Schyns, Sep 2003)
Abstract
Everyone has seen a human face in a cloud, a pebble, or blots on a wall. Evidence of superstitious perceptions has been documented since classical antiquity, but has received little scientific attention. In the study reported here, we used superstitious perceptions in a new principled method to reveal the properties of unobservable object representations in memory. We stimulated the visual system with unstructured white noise. Observers firmly believed that they perceived the letter S in Experiment 1 and a smile on a face in Experiment 2. Using reverse correlation and computational analyses, we rendered the
memory representations underlying these superstitious perceptions.
Let me re-cap the first portion of the experiment, starting with a quote from the "Methods and Results" (ibid):
Method:
In Experiment 1, we instructed 3 paid naive observers (R.C., N.L., and M.J.; ages 21 to 24) to detect in white noise the presence of a target black letter S on a white background filling the image. The observers were told that the letter
S (for "superstitious") was present on 50% of the 20,000 trials, which were equally divided into 40 blocks and completed over a fortnight. No more detail was given regarding the shape of the letter. The image presented on each trial consisted of static bit noise spanning 50 _ 50 pixels (2° _ 2° of visual angle), with a blackpixel density of 50%. No signal was ever presented. The experiment ran on a G4 Macintosh computer using a program written with the Psychophysics Toolbox for Matlab (Brainard, 1997; Pelli, 1997).
Results:
The observers detected an S in noise on 22.7% (R.C.), 45.9% (N.L.), and 11% (M.J.) of the trials, respectively. They claimed that they responded positively whenever they saw an S and estimated the quantity of added noise to vary between 30% and 50%. Observer R.C. described her response strategy as, “I simply waited to see if the S jumped out at me.” To depict the information eliciting these superstitious perceptions, we applied reverse correlation. For each observer, we computed a “yes image” (vs. “no image”) by adding together all the stimuli leading to detections (vs. rejections). We then subtracted the no image from the yes image to produce a classification image (see Fig. 1, inset a, for R.C., N.L., and M.J.). For each observer, the classification image represents the template of information that drove the detection of the target S letter; formally, it is the best least square linear fit to the detection data. 1
Fig 1 (Gosselin, Schyns, Sep 2003)
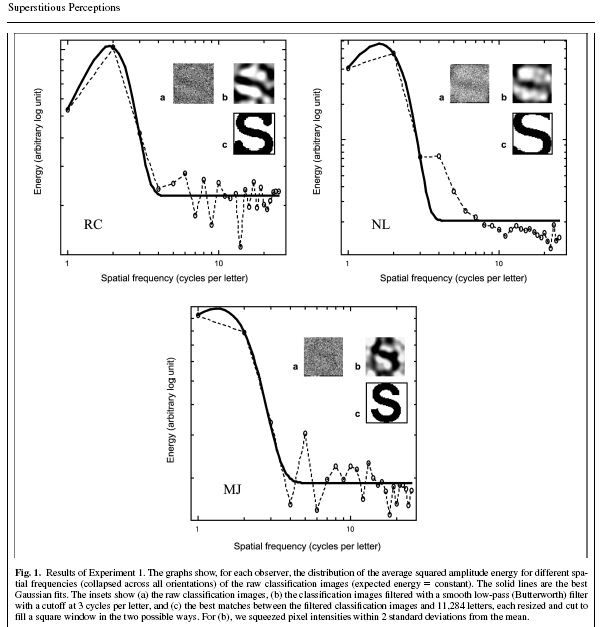
Please see the paper for the statistical analysis that was done on the resultant S es.
When I finished reading this paper, there was something that I didn't understand about Fig. 1. Namely, I didn't grasp why I could see the "S" in boxes "a". If it was white noise, why did I see it. I was missing a very important point though. I wrote to Dr. Schyns again, and asked him my question, to which he replied in part:
In the experiment, we only show white noise templates (many of them). We INSTRUCT subject that there is a letter S (though we are now replicating the results with "a face") in the noise, on 50% of the trials, but there is NEVER such S letter with added noise. We ask subjects to respond on one key when they perceive the S and on another key when they do not perceive the S. After 20,000 trials, we sum together all the white noise templates on which the subject "superstitiously" saw the S. In a separate sum, we sum all the templates on which the subject did not perceive the S. Then, we substract sum1 (I see the S) to sum2 (I do not see the S). Box a of Fig 1 represents this subtraction. Box a therefore represents, for each subject, the information that, on average, distinguished an S from noise IN AN EXPERIMENT WHEN ONLY WHITE NOISE WAS PRESENTED.
How does this happen? Because the subject IS TOLD to EXTRACT the letter S from white noise, the subject attempts to match his/her knowledge of an S with the incoming white noise. To the extent that white noise correlates with all possible patterns, if there is a SMALL but systematic correlation between the knowledge of the subject and the incoming white noise then the subtraction explained above will capture it.
My point of relaying this to you is to show that even under the worst possible condition of information (i.e. absence of it, white noise), people will systematically perceive things. I wish to stress this: they will PERCEIVE something. They are not deluding themselves. If they were (i.e. if there was no systematic correlation between some white noise templates and their knowledge), box a would be a uniform gray. (PG Schyns, personal correspondence)
Now, I strongly urge the reader to re-read Dr. Schyns answer a couple of times. I really can't improve on his words. The subjects were TOLD there was an S in 50% of the slides, and they use their knowledge of an S to actually find systematic data in 100% white noise that best correlates to their idea of an S!!
So, I decided to do a little experiment of my own. I cropped out the three Box “a” from the paper, and applied three simple image processing techniques that I frequently use. Here's the before and after:
Before ("Yeses" and "Nos", summed and subtracted)

My image processed results:

Now, two things I have been thinking all along (one of which I've said many times) is that (a) I believe pareidolia is personal in that it manifests itself differently in different people, and (b) some people are better at it than others (or, maybe a better way of saying that would be that some people are more inclined to it than others).
Two conclusions immediately jumped out at me, when viewing my processed Box a images.
1. There is a direct correlation between the number of times a subject thought he/she saw and S, and the clarity of the S, itself (although the sample size of 3 must limit our appreciation of this fact). NL saw an "S" 45.9% of the time, so his "S" came out pretty good. He was good at it! But, MJ really didn't see the "S" all that often, so his came out pretty blurry. RC was in the middle, and so was the clarity of his "S".
2. They each saw a different kind of S:
"To test that the S s in the classification images were not simply the result of our own superstitious perceptions, we correlated these classification images with the 26 letters of the alphabet from 31 fonts, in 7 styles (normal, italic, bold, underline, outline, condense, extend) and in upper- and lowercase, for a total of 11,284 Pearson correlations. All letters were resized and cut to fill a square window in the two possible ways (i.e., with the width of the letter occupying the whole width of the window or the height of the letter occupying the whole height of the window). The highest correlations were obtained with the following letters (see Fig. 1, inset c, for each observer): for R.G., an uppercase Courier New bold S scaled horizontally ( r _ .557); for N.L., a lowercase Verdana regular-style S scaled horizontally (R _.553); and for M.L., an uppercase Arial bold S scaled vertically ( r_.704). On average, confounding font, style, case, and observer, the largest correlation between the classification images and the 26 letters of the alphabet was found for S (see Fig. 2), a pattern true for each observer." (ibid)
I'll leave it to the reader to draw his or her own conclusions as to the relevancy of this study to the pareidolia topic, but Dr. Schyns obviously thought it was relevant, and so do I. As a matter of fact, it was the conclusion in (2) above that first got me thinking we were in fact dealing with pareidolia in the first place. And it's not too big of a leap to say we've seen (1) manifested over and over again.
rd
One day I was searching the web via Google for "Faces" or "Face Studies" and various things of that nature, when I came across an interesting paper by the name of “Dr. Angry and Mr. Smile: when categorization flexibly modifies the perception of faces in rapid visual presentations by Philippe G. Schyns*, Aude Oliva* Department of Psychology, University of Glasgow,UK
I wouldn't attempt to summarize a paper of this complexity here, but for anyone who is interested, it is readily available on the internet. Here's one site: cvcl.mit.edu/Papers/Schyns-Oliva99.pdf#s...and%20Mr.%20Smile%22
The study uses something called "hybrid images", where two different categories of face features are overlapped at different spatial frequencies. Here is an example of a hybrid, from the paper (step back from the screen, and you will see Dr. Angry turn into Mr. Smile, and vice versa):
(From PG Schyns, A. Oliva99)

As I read through this paper, I started to get the distinct impression that this was somehow related to my study of pareidolia, although there is no mention of the subject. After reading it, I wrote to Dr. Schyns at his email address on the paper, at the University of Glasgow's Department of Psychology. I told him that I had just read “Dr. Angry and Mr. Smile” and that how I really stumbled upon it accidentally, while trying to find out more about pareidolia, and asked him if he knew of any studies being done on pareidolia. He was on vacation at the time, but when he got back, he kindly responded and sent me a copy of a 5 page paper by the called: "SUPERSTITIOUS PERCEPTIONS REVEAL PROPERTIES OF INTERNAL REPRESENTATIONS" Frederic Gosselin and Philippe G. Schyns (sorry, but I have no link, so anyone interested will have to request a copy)
He asked me not to be put off by the title, and that he thought I might find it relevant to my question. He was right! It is very much relevant.
I'll copy the Abstract, and then give a brief description of the experiment, results, and conclusions.
Abstract (Superstitious, Frederic Gosselin and Philippe G. Schyns, Sep 2003)
Abstract
Everyone has seen a human face in a cloud, a pebble, or blots on a wall. Evidence of superstitious perceptions has been documented since classical antiquity, but has received little scientific attention. In the study reported here, we used superstitious perceptions in a new principled method to reveal the properties of unobservable object representations in memory. We stimulated the visual system with unstructured white noise. Observers firmly believed that they perceived the letter S in Experiment 1 and a smile on a face in Experiment 2. Using reverse correlation and computational analyses, we rendered the
memory representations underlying these superstitious perceptions.
Let me re-cap the first portion of the experiment, starting with a quote from the "Methods and Results" (ibid):
Method:
In Experiment 1, we instructed 3 paid naive observers (R.C., N.L., and M.J.; ages 21 to 24) to detect in white noise the presence of a target black letter S on a white background filling the image. The observers were told that the letter
S (for "superstitious") was present on 50% of the 20,000 trials, which were equally divided into 40 blocks and completed over a fortnight. No more detail was given regarding the shape of the letter. The image presented on each trial consisted of static bit noise spanning 50 _ 50 pixels (2° _ 2° of visual angle), with a blackpixel density of 50%. No signal was ever presented. The experiment ran on a G4 Macintosh computer using a program written with the Psychophysics Toolbox for Matlab (Brainard, 1997; Pelli, 1997).
Results:
The observers detected an S in noise on 22.7% (R.C.), 45.9% (N.L.), and 11% (M.J.) of the trials, respectively. They claimed that they responded positively whenever they saw an S and estimated the quantity of added noise to vary between 30% and 50%. Observer R.C. described her response strategy as, “I simply waited to see if the S jumped out at me.” To depict the information eliciting these superstitious perceptions, we applied reverse correlation. For each observer, we computed a “yes image” (vs. “no image”) by adding together all the stimuli leading to detections (vs. rejections). We then subtracted the no image from the yes image to produce a classification image (see Fig. 1, inset a, for R.C., N.L., and M.J.). For each observer, the classification image represents the template of information that drove the detection of the target S letter; formally, it is the best least square linear fit to the detection data. 1
Fig 1 (Gosselin, Schyns, Sep 2003)
Please see the paper for the statistical analysis that was done on the resultant S es.
When I finished reading this paper, there was something that I didn't understand about Fig. 1. Namely, I didn't grasp why I could see the "S" in boxes "a". If it was white noise, why did I see it. I was missing a very important point though. I wrote to Dr. Schyns again, and asked him my question, to which he replied in part:
In the experiment, we only show white noise templates (many of them). We INSTRUCT subject that there is a letter S (though we are now replicating the results with "a face") in the noise, on 50% of the trials, but there is NEVER such S letter with added noise. We ask subjects to respond on one key when they perceive the S and on another key when they do not perceive the S. After 20,000 trials, we sum together all the white noise templates on which the subject "superstitiously" saw the S. In a separate sum, we sum all the templates on which the subject did not perceive the S. Then, we substract sum1 (I see the S) to sum2 (I do not see the S). Box a of Fig 1 represents this subtraction. Box a therefore represents, for each subject, the information that, on average, distinguished an S from noise IN AN EXPERIMENT WHEN ONLY WHITE NOISE WAS PRESENTED.
How does this happen? Because the subject IS TOLD to EXTRACT the letter S from white noise, the subject attempts to match his/her knowledge of an S with the incoming white noise. To the extent that white noise correlates with all possible patterns, if there is a SMALL but systematic correlation between the knowledge of the subject and the incoming white noise then the subtraction explained above will capture it.
My point of relaying this to you is to show that even under the worst possible condition of information (i.e. absence of it, white noise), people will systematically perceive things. I wish to stress this: they will PERCEIVE something. They are not deluding themselves. If they were (i.e. if there was no systematic correlation between some white noise templates and their knowledge), box a would be a uniform gray. (PG Schyns, personal correspondence)
Now, I strongly urge the reader to re-read Dr. Schyns answer a couple of times. I really can't improve on his words. The subjects were TOLD there was an S in 50% of the slides, and they use their knowledge of an S to actually find systematic data in 100% white noise that best correlates to their idea of an S!!
So, I decided to do a little experiment of my own. I cropped out the three Box “a” from the paper, and applied three simple image processing techniques that I frequently use. Here's the before and after:
Before ("Yeses" and "Nos", summed and subtracted)

My image processed results:

Now, two things I have been thinking all along (one of which I've said many times) is that (a) I believe pareidolia is personal in that it manifests itself differently in different people, and (b) some people are better at it than others (or, maybe a better way of saying that would be that some people are more inclined to it than others).
Two conclusions immediately jumped out at me, when viewing my processed Box a images.
1. There is a direct correlation between the number of times a subject thought he/she saw and S, and the clarity of the S, itself (although the sample size of 3 must limit our appreciation of this fact). NL saw an "S" 45.9% of the time, so his "S" came out pretty good. He was good at it! But, MJ really didn't see the "S" all that often, so his came out pretty blurry. RC was in the middle, and so was the clarity of his "S".
2. They each saw a different kind of S:
"To test that the S s in the classification images were not simply the result of our own superstitious perceptions, we correlated these classification images with the 26 letters of the alphabet from 31 fonts, in 7 styles (normal, italic, bold, underline, outline, condense, extend) and in upper- and lowercase, for a total of 11,284 Pearson correlations. All letters were resized and cut to fill a square window in the two possible ways (i.e., with the width of the letter occupying the whole width of the window or the height of the letter occupying the whole height of the window). The highest correlations were obtained with the following letters (see Fig. 1, inset c, for each observer): for R.G., an uppercase Courier New bold S scaled horizontally ( r _ .557); for N.L., a lowercase Verdana regular-style S scaled horizontally (R _.553); and for M.L., an uppercase Arial bold S scaled vertically ( r_.704). On average, confounding font, style, case, and observer, the largest correlation between the classification images and the 26 letters of the alphabet was found for S (see Fig. 2), a pattern true for each observer." (ibid)
I'll leave it to the reader to draw his or her own conclusions as to the relevancy of this study to the pareidolia topic, but Dr. Schyns obviously thought it was relevant, and so do I. As a matter of fact, it was the conclusion in (2) above that first got me thinking we were in fact dealing with pareidolia in the first place. And it's not too big of a leap to say we've seen (1) manifested over and over again.
rd
Please Log in or Create an account to join the conversation.
- tvanflandern
-
- Offline
- Platinum Member
-
Less
More
- Thank you received: 0
18 years 7 months ago #9167
by tvanflandern
Replied by tvanflandern on topic Reply from Tom Van Flandern
<blockquote id="quote"><font size="2" face="Verdana, Arial, Helvetica" id="quote">quote:<hr height="1" noshade id="quote"><i>Originally posted by rderosa</i>
<br />I’ll leave it to the reader to draw his or her own conclusions as to the relevancy of this study to the pareidolia topic<hr height="1" noshade id="quote"></blockquote id="quote"></font id="quote">As I read through the experimental protocol, I tried to imagine myself as a subject viewing white noise and searching for "S"es. I doubted that I would see anything that would look sufficiently like an "S" to get me to respond.
Then I read where the subjects were told that half the screens had an embedded "S". Armed with that information, after a few sample screens I would get the idea that I was not looking for a normal "S", but rather a broken "S" disguised or hidden in noise -- much like detecting a building ot tank hidden by camouflage. But that changes the whole experiment into a guessing game. How many S-like dark areas are needed before one can call it a hidden "S"? I would recalibrate my criteria, accepting poorer and poorer representations, until I got close to my designated "quota" of 50% of the images.
The point is that I would not really be seeing "S"es or anything I would mistake for an "S" in real life. I would simply be adapting and learning how to respond to a very specific type of stimulus. You might as well have given me a bunch of white noise images and told me to pick out about half of the images that have the best approximation to showing an "S". There is a solution to that challenge (though not a unique one), and an obedient subject would do as requested.
The absence of controls in the experimental protocol stood out for me as a red warning flag. Because there is no control group, it is impossible to attribute the test result to anything specific. The power of suggestion comes readily to mind.
A slightly more relevant test would be to say that the letter "S" might or might not be hidden in some of the images to be shown. Then suggestible persons or those who more quickly spot patterns in noise would probably have a few hits, while many other subjects would find none. But that doesn't really tell us anything we didn't already know.
So my initial reaction to this test is that it has little to tell us about our Mars dilemma. However, it is the kind of challenge we need. I'll bet somone out there has done some testing that is more relevant to our situation, if we can just find that information. -|Tom|-
<br />I’ll leave it to the reader to draw his or her own conclusions as to the relevancy of this study to the pareidolia topic<hr height="1" noshade id="quote"></blockquote id="quote"></font id="quote">As I read through the experimental protocol, I tried to imagine myself as a subject viewing white noise and searching for "S"es. I doubted that I would see anything that would look sufficiently like an "S" to get me to respond.
Then I read where the subjects were told that half the screens had an embedded "S". Armed with that information, after a few sample screens I would get the idea that I was not looking for a normal "S", but rather a broken "S" disguised or hidden in noise -- much like detecting a building ot tank hidden by camouflage. But that changes the whole experiment into a guessing game. How many S-like dark areas are needed before one can call it a hidden "S"? I would recalibrate my criteria, accepting poorer and poorer representations, until I got close to my designated "quota" of 50% of the images.
The point is that I would not really be seeing "S"es or anything I would mistake for an "S" in real life. I would simply be adapting and learning how to respond to a very specific type of stimulus. You might as well have given me a bunch of white noise images and told me to pick out about half of the images that have the best approximation to showing an "S". There is a solution to that challenge (though not a unique one), and an obedient subject would do as requested.
The absence of controls in the experimental protocol stood out for me as a red warning flag. Because there is no control group, it is impossible to attribute the test result to anything specific. The power of suggestion comes readily to mind.
A slightly more relevant test would be to say that the letter "S" might or might not be hidden in some of the images to be shown. Then suggestible persons or those who more quickly spot patterns in noise would probably have a few hits, while many other subjects would find none. But that doesn't really tell us anything we didn't already know.
So my initial reaction to this test is that it has little to tell us about our Mars dilemma. However, it is the kind of challenge we need. I'll bet somone out there has done some testing that is more relevant to our situation, if we can just find that information. -|Tom|-
Please Log in or Create an account to join the conversation.
- neilderosa
-
- Offline
- Platinum Member
-
Less
More
- Thank you received: 0
18 years 7 months ago #9169
by neilderosa
Replied by neilderosa on topic Reply from Neil DeRosa
I have several questions and a few preliminary remarks. Once we get your answers I will be able to draw further conclusions on the meaning of this study.
1- “naive observers.” Please define this term.
2- “The observers were told that the letter S (for “superstitious”) was present on 50% of the 20,000 trials, which were equally divided into 40 blocks and completed over a fortnight.” Was this true, in other words were the test subjects told the truth?
3- “The image presented on each trial consisted of static bit noise.” Does this mean that the image was all “noise,” or was an ”S” actually imbedded in the image 50% of the time?
4- “The observers detected an S in noise on 22.7% (R.C.), 45.9% (N.L.), and 11% (M.J.) of the trials, respectively.” Am I correct in assuming that the “S” was actually there 50% of the time, but this was the rate of its appearance perceived by the test subjects?
5- “In the experiment, we only show white noise templates (many of them). We INSTRUCT subject that there is a letter S in the noise, on 50% of the trials, but there is NEVER such S letter with added noise.” Does this mean that in the twenty thousand trials there is never an “S” actually in the image? If so, are the several samples of “a” in your post, genuine excerpts from the study, or are they “modified” to render the explanation clearer and easier to understand? In other words, I want to know whether I am also imagining the “S” by my own power of suggestion (because I also see the real S’s) or whether the “S” is really there in the noise images “a”.
6- “Box a therefore represents, for each subject, the information that, on average, distinguished an S from noise IN AN EXPERIMENT WHEN ONLY WHITE NOISE WAS PRESENTED.” Again, are WE seeing the same (real) “box a” with only noise in it?
7- “How does this happen? Because the subject IS TOLD to EXTRACT the letter S from white noise, the subject attempts to match his/her knowledge of an S with the incoming white noise.” Forgive me if I don’t take the experimenter’s word for this. Any valid scientific study must be repeatable, so others can do the same experiment and get the same results. This is what JP did in his “Profile” paper in MRB, we could actually do the optical illusion tests and see for ourselves. This is also what we did in our “T or E” paper; we showed the reader how to overcome the light inversion effect.
8- “So, I decided to do a little experiment of my own. I cropped out the three Box “a” from the paper, and applied three simple image processing techniques that I frequently use. Here’s the before and after:” The three “a” boxes you processed all had “S” included in with the noise, so was the “S” included or were the “a” boxes only noise? In other words, are we imagining that we see "S" in your processed images also? Please inform us.
Neil
1- “naive observers.” Please define this term.
2- “The observers were told that the letter S (for “superstitious”) was present on 50% of the 20,000 trials, which were equally divided into 40 blocks and completed over a fortnight.” Was this true, in other words were the test subjects told the truth?
3- “The image presented on each trial consisted of static bit noise.” Does this mean that the image was all “noise,” or was an ”S” actually imbedded in the image 50% of the time?
4- “The observers detected an S in noise on 22.7% (R.C.), 45.9% (N.L.), and 11% (M.J.) of the trials, respectively.” Am I correct in assuming that the “S” was actually there 50% of the time, but this was the rate of its appearance perceived by the test subjects?
5- “In the experiment, we only show white noise templates (many of them). We INSTRUCT subject that there is a letter S in the noise, on 50% of the trials, but there is NEVER such S letter with added noise.” Does this mean that in the twenty thousand trials there is never an “S” actually in the image? If so, are the several samples of “a” in your post, genuine excerpts from the study, or are they “modified” to render the explanation clearer and easier to understand? In other words, I want to know whether I am also imagining the “S” by my own power of suggestion (because I also see the real S’s) or whether the “S” is really there in the noise images “a”.
6- “Box a therefore represents, for each subject, the information that, on average, distinguished an S from noise IN AN EXPERIMENT WHEN ONLY WHITE NOISE WAS PRESENTED.” Again, are WE seeing the same (real) “box a” with only noise in it?
7- “How does this happen? Because the subject IS TOLD to EXTRACT the letter S from white noise, the subject attempts to match his/her knowledge of an S with the incoming white noise.” Forgive me if I don’t take the experimenter’s word for this. Any valid scientific study must be repeatable, so others can do the same experiment and get the same results. This is what JP did in his “Profile” paper in MRB, we could actually do the optical illusion tests and see for ourselves. This is also what we did in our “T or E” paper; we showed the reader how to overcome the light inversion effect.
8- “So, I decided to do a little experiment of my own. I cropped out the three Box “a” from the paper, and applied three simple image processing techniques that I frequently use. Here’s the before and after:” The three “a” boxes you processed all had “S” included in with the noise, so was the “S” included or were the “a” boxes only noise? In other words, are we imagining that we see "S" in your processed images also? Please inform us.
Neil
Please Log in or Create an account to join the conversation.
18 years 7 months ago #17419
by rderosa
Replied by rderosa on topic Reply from Richard DeRosa
<blockquote id="quote"><font size="2" face="Verdana, Arial, Helvetica" id="quote">quote:<hr height="1" noshade id="quote"><i>Originally posted by tvanflandern</i>
<br />As I read through the experimental protocol, I tried to imagine myself as a subject viewing white noise and searching for "S"es. I doubted that I would see anything that would look sufficiently like an "S" to get me to respond.<hr height="1" noshade id="quote"></blockquote id="quote"></font id="quote">Tom, you bring up a good point, but I would refer you to the first sentence of the "Method":
**In Experiment 1, we instructed 3 paid naive observers (R.C., N.L.,
and M.J.; ages 21 to 24) to detect in white noise the presence of a target black letter S on a white background filling the image.**
Now, that jumped out at me when I read it. I got it, or at least I thought I got it, right away. It's not necessarily going to work on you or me, or most of the participants/readers of the forum. We have too much history with this stuff.
Let me give you a quick analogy. When I was in my late teens until about age 30ish, I read at least 50 to 60 of Agatha Christie's mysteries. I had a list one time, so I knew which ones I had read. But now, today, without the list, if the opening page (or scene if it was a movie) started with a girl running up to Hercule Poirot gasping, "Monsior Poirot, someone is trying to kill me!" The first thing I would think is that she's going to end up being the murderer.
It got to the point where I couldn't read any more of them, because I couldn't tell if I had read it before.
But the fact that it wouldn't work on you, doesn't change the basic premise. With all due respect, I think you're overthinking this. Based upon my understanding of this, which I think Dr. Schyns has validated, you may be missing the main point.
The whole point is that the subject HAS TO believe the S is there. <b>But there is no S there in the data.</b> I don't know how to make that any clearer or stronger, but it's crucial. This is not a case of "power of suggestion". The instructor is telling the subject there are Ss in 50% of the samples (they didn't explain the exact steps that were taken). He WANTS the subject to KNOW that the Ss are there.
The purpose of the experiment is to show how what we know influences what we perceive. I'm currently reading something much more in depth on this subject called:
"The development of features in object concepts" Philippe G. Schyns, Robert L. Goldstone,Jean-Pierre Thibaut", of which:
"The main idea of the paper is that "experience with categorizing things" (what one could call "expertise" with an object category) can modify the way one encodes and perceives them.
"The idea is that one builds a space to encode objects (by analogy the dimensions of a n-dimensional space) that is experience dependent. One then projects the incoming object onto these dimensions. If the dimensions vary across observers, then their perception of the same object will also vary." (PG Schyns, personal correspondence)
Regarding this subject, in general, and the Superstitious paper in particular, Dr. Schyns said, ".... this is the idea that one sees what one knows..." This is the main idea in, "Dr. Angry and Mr. Smile" also.
Again, the paper is only 5 pages long, so I strongly suggest that those interested get a copy and read it. After I read it, I only had one question, which was quickly answered, and then I had one follow-up, which is current now. I don't want to try to be a spokesperson for Dr. Schyns, which I'm sure he'd agree with.
All I'm saying is that I think I understand the point of the experiment, and the results, and that it appears that I'm in concert with the authors in my understanding.
I'm open to other interpretations any one comes to after reading it.
rd
<br />As I read through the experimental protocol, I tried to imagine myself as a subject viewing white noise and searching for "S"es. I doubted that I would see anything that would look sufficiently like an "S" to get me to respond.<hr height="1" noshade id="quote"></blockquote id="quote"></font id="quote">Tom, you bring up a good point, but I would refer you to the first sentence of the "Method":
**In Experiment 1, we instructed 3 paid naive observers (R.C., N.L.,
and M.J.; ages 21 to 24) to detect in white noise the presence of a target black letter S on a white background filling the image.**
Now, that jumped out at me when I read it. I got it, or at least I thought I got it, right away. It's not necessarily going to work on you or me, or most of the participants/readers of the forum. We have too much history with this stuff.
Let me give you a quick analogy. When I was in my late teens until about age 30ish, I read at least 50 to 60 of Agatha Christie's mysteries. I had a list one time, so I knew which ones I had read. But now, today, without the list, if the opening page (or scene if it was a movie) started with a girl running up to Hercule Poirot gasping, "Monsior Poirot, someone is trying to kill me!" The first thing I would think is that she's going to end up being the murderer.
It got to the point where I couldn't read any more of them, because I couldn't tell if I had read it before.
But the fact that it wouldn't work on you, doesn't change the basic premise. With all due respect, I think you're overthinking this. Based upon my understanding of this, which I think Dr. Schyns has validated, you may be missing the main point.
The whole point is that the subject HAS TO believe the S is there. <b>But there is no S there in the data.</b> I don't know how to make that any clearer or stronger, but it's crucial. This is not a case of "power of suggestion". The instructor is telling the subject there are Ss in 50% of the samples (they didn't explain the exact steps that were taken). He WANTS the subject to KNOW that the Ss are there.
The purpose of the experiment is to show how what we know influences what we perceive. I'm currently reading something much more in depth on this subject called:
"The development of features in object concepts" Philippe G. Schyns, Robert L. Goldstone,Jean-Pierre Thibaut", of which:
"The main idea of the paper is that "experience with categorizing things" (what one could call "expertise" with an object category) can modify the way one encodes and perceives them.
"The idea is that one builds a space to encode objects (by analogy the dimensions of a n-dimensional space) that is experience dependent. One then projects the incoming object onto these dimensions. If the dimensions vary across observers, then their perception of the same object will also vary." (PG Schyns, personal correspondence)
Regarding this subject, in general, and the Superstitious paper in particular, Dr. Schyns said, ".... this is the idea that one sees what one knows..." This is the main idea in, "Dr. Angry and Mr. Smile" also.
Again, the paper is only 5 pages long, so I strongly suggest that those interested get a copy and read it. After I read it, I only had one question, which was quickly answered, and then I had one follow-up, which is current now. I don't want to try to be a spokesperson for Dr. Schyns, which I'm sure he'd agree with.
All I'm saying is that I think I understand the point of the experiment, and the results, and that it appears that I'm in concert with the authors in my understanding.
I'm open to other interpretations any one comes to after reading it.
rd
Please Log in or Create an account to join the conversation.
Time to create page: 0.418 seconds